In this article, you will learn the effective product recommendations method (the so-called cart analysis). By using a special algorithm (Apriori algorithm), you will learn which products to sell in sets. Let's learn about the product recommendation engine (Apriori algorithm cart analysis) and increase the average cart value in your WooCommerce store.
➡️ Have you ever wondered why people do not buy cross-sell products?
Read the article to see how to boost the Product Recommendation engine in WooCommerce. Let's begin!
Table of contents
- Intelligent product recommendations - cross-selling
- Apriori algorithm - recommendation engine in a nutshell
- Tips for an effective recommendation engine for WooCommerce
- The principle of operation of the Apriori Algorithm
- Summary
Intelligent product recommendations - cross-selling
One of the methods of increasing sales in the online store is the recommendation of related products.
Unfortunately, the most common implementation of such recommendations is displaying products from the same category. Under the product we are viewing, we see other products of this type - e.g. other footwear offers.
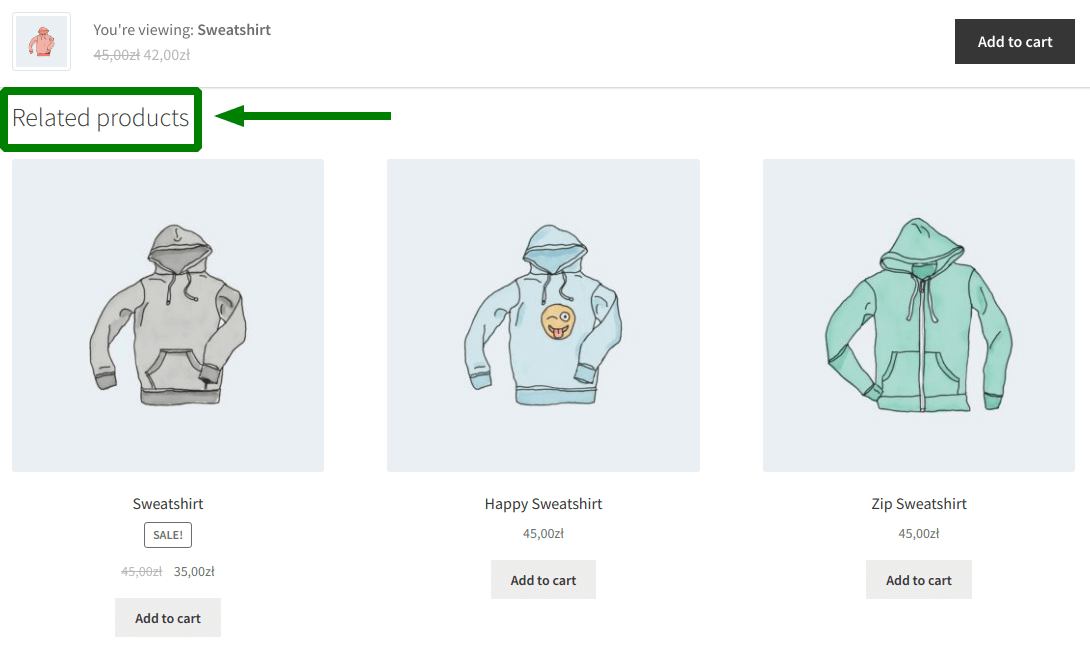
However, the relationship between products does not result from the joint category in which they were added to the store. Recommending other shoes when the customer has already put one pair into the cart has no sense, whatsoever. This way, we make blind guesses about whether this works. Maybe the customer will add something else to the cart.
The essence of product recommendations is to give the customers a product that they will be interested in. How do we know what these products are? Thanks to statistics! With its help, we can find out that the majority of customers buying product A, also buy B and C. In this case, we recommend B and C to the customer who puts A in the cart. This kind of product recommendation works best on the cart page.
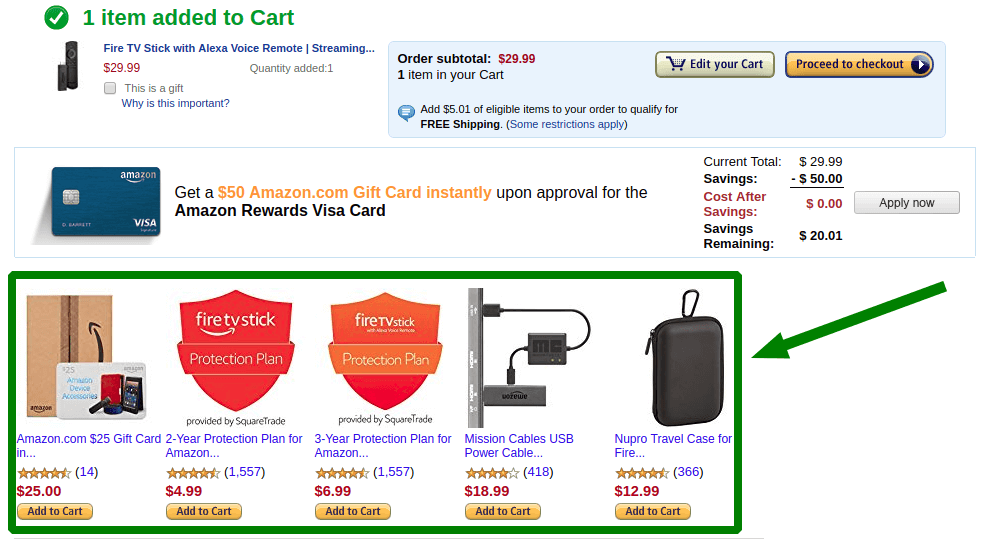
This way, the customers making the purchase get information that they can buy other items. We perceive a certain purchasing trend and we facilitate its implementation to subsequent customers.
Thanks to a convenient interface, subsequent customers will add additional products to their orders. The value of the cart will increase. The store will earn more. Everyone is happy :)
In the case of such upselling, you can apply a discount on the product upsold. This way, customer satisfaction with the purchase will increase.
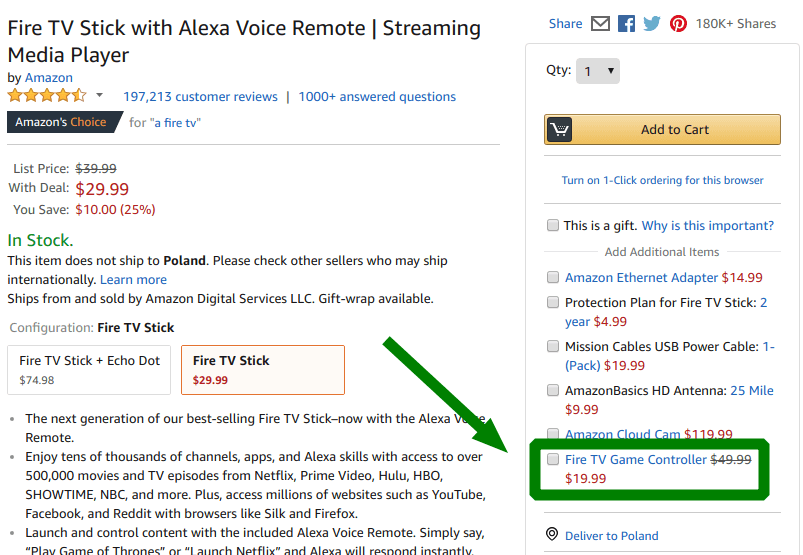
Apriori algorithm - recommendation engine in a nutshell
What is the cart analysis?
Question - how to take useful data from product orders for product recommendations? The answer is the so-called cart analysis. It is a method of data mining.
An efficient and popular algorithm for cart analysis is the Apriori algorithm. This algorithm defines how we mine data and how we evaluate its usefulness.
Not every correlation of products in the customer's cart will be used for recommendations. If a case happened 1 time in 1000, then there is no point in implementing such a recommendation at the store level. This is not a trend, but a single case.
But we need to find a recommendation engine for our store (like WooCommerce). Let's see an example!
Examples of effective implementation
Online we can find information that the cart analysis was used by Wal-Mart in the 1990s. It is one of the largest hypermarket chains in the United States. Thanks to the cart analysis, a strong relationship between beer and diapers was discovered. You would not come up with something like this on your own, such strange correlations result from data mining.
Let us get to the point: beer and baby diapers were often bought on Friday nights by young men.
Thanks to this knowledge, analysts have introduced changes in the store.
First, they put these products closer together.
Second, they modified marketing activities.
A large hypermarket applies all promotions and discounts on products. On Fridays, it was decided that only one of the two products will be discounted. In most cases, both of them will be purchased anyhow. This way, the store gained additional sales and saved on marketing activities.
Many of the principles and methods used in the analysis of traditional stores can also be applied to e-commerce. Some of them are easier to implement. Our online stores can be easily monitored - clicks, traffic, and time spent on the site. It is also worth using the data on products in the cart to improve the recommendation engine in a store (like WooCommerce).
Tips for an effective recommendation engine for WooCommerce
The Apriori algorithm does not only show the relations between products, but thanks to its design it allows you to reject insignificant data. For this purpose, it introduces two important concepts:
- support - frequency of occurrence
- confidence - certainty of the rule
The algorithm makes it possible to determine the minimum values for these two indicators. Thus, we reject transactions that do not meet the quality assumptions for the recommendation.
The operation of this algorithm is iterative. We do not process all data at once. Thanks to this, the algorithm limits the number of calculations on the database.
I will show you the operation of the algorithm in practice. I will explain the use of support and confidence as key elements of the Apriori algorithm.
The principle of operation of the Apriori Algorithm
Initial assumptions for example
Let us use a simplified example.
Let us assume that we have four products in our store: A, B, C, D. Customers have made 7 transactions, which look like this:
- A, B, C, D
- A, B
- B, C, D
- A, B, D
- B, C
- C, D
- B, D
We will use Apriori to determine the relationships between the products. As the support, we set the value to 3. This means that the rule must occur 3 times in the given iteration.
1️⃣ The first iteration
Let us start the first iteration. We determine how often the product appeared in the orders:
- A - 3 times
- B - 6 times
- C - 4 times
- D - 5 times
Each of these products appeared in the orders more than 3 times. All products meet the support requirements. We will use each of them in the next iteration.
2️⃣ The second iteration
We now look for connections in products based on a set of two products. We look for how often customers put together two selected products in one order.
- A, B - 3 times
- A, C - 1 time
- A, D - 2 times
- B, C - 3 times
- B, D - 4 times
- C, D - 3 times
As you can see, sets {A, C} and {A, D} do not meet the assumptions of support. They occur less than three times. Therefore, we exclude them from the next iteration.
3️⃣ Third iteration
We look for sets consisting of three products, which:
- occurred in customer orders
- do not contain sets {A, C} and {A, D} in themselves
It is therefore a set of {B, C, D}. It occurs in orders only two times, so it does not meet our support assumptions.
Result
Our assumptions meet the following sets:
- A, B - occurred three times in orders
- B, C - 3 times as well
- B, D - 4 times
This example was only meant to illustrate the operation of the algorithm. For most online stores, calculations on data will be much more complicated, as there will be more of them.
Support expressed in percent
It is worth adding that support defines the global share of the rule in all transactions. We agreed to support our minimum requirements as a numerical value: 3. However, we could set a percentage. In this case:
- A, B have support equal to approximately 42.9% - they occur 3 times for 7 transactions
- B, C have the same support
- B, D have support equal to approximately 57.14% - they occur 4 times for 7 transactions
High percentages of the support factor result from a small number of products in our example. We have only 4 products: A, B, C, and D.
It is very unlikely that in a store with, for example, 1000 products, there were always two identical products in half of the orders.
This example is deliberately simplified. You should take it into account when using the algorithm in your store. You should set the minimum value of support individually for the store, industry, etc.
Conclusions
The question of confidence remains. It specifies the occurrence of a given rule to all those where the initial set occurred.
➡️ How to calculate it?
{A, B} - occurred three times in orders The initial set is A. This product has also appeared in orders three times. The confidence is therefore 100%.
Let us mirror image this pair. {B, A} occurred in orders 3 times. Nothing has changed here - the pair is the same. However, the initial set changes. This is B. This product has occurred in 6 transactions. This gives us confidence at the level of 50%. Product A occurred only in half of the transactions in which product B occurred.
- A and B have 100% confidence
- B and A have 50% confidence
- B and C have 50% confidence
- C and B have 75% confidence
- B and D have 66.7% confidence
- D and B have 80% confidence
Our simplified example (4 products, 7 transactions) gives birth to the following recommendations:
- A -> B
- B -> D
- C -> B
- D -> B
where the first product is the one a user adds to the cart. The second one is this that we recommend.
Summary
Cart analysis is a very effective method for the product recommendation system (also for WooCommerce). However, I cannot imagine manual data processing according to the above algorithm. Especially with larger stores.
An effective cart analysis requires a convenient implementation. The Apriori algorithm should work on the principle of a program, not manual data processing.
There is an implementation of the Apriori Algorithm in Python on the network.
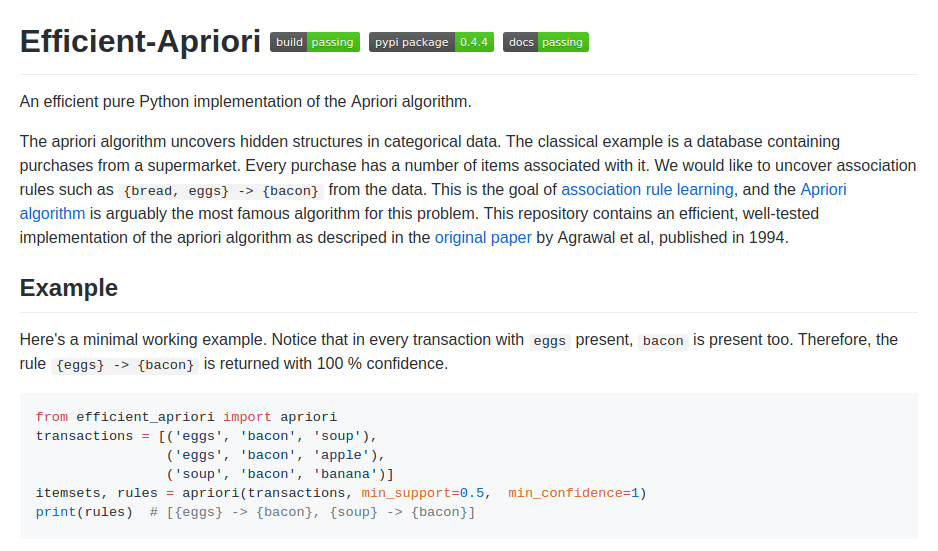
However, as you can see in the screenshot, it requires programming skills to use it.
👉🏼 Does a convenient implementation of the Apriori Algorithm in WooCommerce interest you? Let me know in the comment section below.
Download it directly from the link below ⤵️ ⤵️ ⤵️
Flexible Product Fields WooCommerce
Create a product wizard to sell engravings, gift wrapping, gift messages, business cards, stamps and optionally charge for it (fixed or percentage).
💾 Active Installations: 10,000+ | WordPress Rating:
Download for free or Go to WordPress.orgRelated to product recommendation WooCommerce
-
Advanced custom fields

WooCommerce advanced custom fields. Find out how to add advanced product and checkout fields for WooCommerce. -
WooCommerce tips and tricks

WooCommerce tips. Get to know the 5 essential WooCommerce tips to boost your sales.
